






















DSPy vs LangChain: A Comprehensive Framework Comparison
Qdrant Team
·February 23, 2024

As Large Language Models (LLMs) and vector stores have become steadily more powerful, a new generation of frameworks has appeared which can streamline the development of AI applications by leveraging LLMs and vector search technology. These frameworks simplify the process of building everything from Retrieval Augmented Generation (RAG) applications to complex chatbots with advanced conversational abilities, and even sophisticated reasoning-driven AI applications.
The most well-known of these frameworks is possibly LangChain. Launched in October 2022 as an open-source project by Harrison Chase, the project quickly gained popularity, attracting contributions from hundreds of developers on GitHub. LangChain excels in its broad support for documents, data sources, and APIs. This, along with seamless integration with vector stores like Qdrant and the ability to chain multiple LLMs, has allowed developers to build complex AI applications without reinventing the wheel.
However, despite the many capabilities unlocked by frameworks like LangChain, developers still needed expertise in prompt engineering to craft optimal LLM prompts. Additionally, optimizing these prompts and adapting them to build multi-stage reasoning AI remained challenging with the existing frameworks.
In fact, as you start building production-grade AI applications, it becomes clear that a single LLM call isn’t enough to unlock the full capabilities of LLMs. Instead, you need to create a workflow where the model interacts with external tools like web browsers, fetches relevant snippets from documents, and compiles the results into a multi-stage reasoning pipeline.
This involves building an architecture that combines and reasons on intermediate outputs, with LLM prompts that adapt according to the task at hand, before producing a final output. A manual approach to prompt engineering quickly falls short in such scenarios.
In October 2023, researchers working in Stanford NLP released a library, DSPy, which entirely automates the process of optimizing prompts and weights for large language models (LLMs), eliminating the need for manual prompting or prompt engineering.
One of DSPy’s key features is its ability to automatically tune LLM prompts, an approach that is especially powerful when your application needs to call the LLM several times within a pipeline.
So, when building an LLM and vector store-backed AI application, which of these frameworks should you choose? In this article, we dive deep into the capabilities of each and discuss scenarios where each of these frameworks shine. Let’s get started!
LangChain: Features, Performance, and Use Cases
LangChain, as discussed above, is an open-source orchestration framework available in both Python and JavaScript, designed to simplify the development of AI applications leveraging LLMs. For developers working with one or multiple LLMs, it acts as a universal interface for these AI models. LangChain integrates with various external data sources, supports a wide range of data types and stores, streamlines the handling of vector embeddings and retrieval through similarity search, and simplifies the integration of AI applications with existing software workflows.
At a high level, LangChain abstracts the common steps required to work with language models into modular components, which serve as the building blocks of AI applications. These components can be “chained” together to create complex applications. Thanks to these abstractions, LangChain allows for rapid experimentation and prototyping of AI applications in a short timeframe.
LangChain breaks down the functionality required to build AI applications into three key sections:
- Model I/O: Building blocks to interface with the LLM.
- Retrieval: Building blocks to streamline the retrieval of data used by the LLM for generation (such as the retrieval step in RAG applications).
- Composition: Components to combine external APIs, services and other LangChain primitives.
These components are pulled together into ‘chains’ that are constructed using LangChain Expression Language (LCEL). We’ill first look at the various building blocks, and then see how they can be combined using LCEL.
LLM Model I/O
LangChain offers broad compatibility with various LLMs, and its LLM class provides a standard interface to these models. Leveraging proprietary models offered by platforms like OpenAI, Mistral, Cohere, or Gemini is straightforward and requires just an API key from the respective platform.
For instance, to use OpenAI models, you simply need to do the following:
from langchain_openai import OpenAI
llm = OpenAI(api_key="...")
llm.invoke("Where is Paris?")
Open-source models like Meta AI’s Llama variants (such as Llama3-8B) or Mistral AI’s open models (like Mistral-7B) can be easily integrated using their Hugging Face endpoints or local LLM deployment tools like Ollama, vLLM, or LM Studio. You can also use the CustomLLM class to build Custom LLM wrappers.
Here’s how simple it is to use LangChain with LlaMa3-8B, using Ollama.
from langchain_community.llms import Ollama
llm = Ollama(model="llama3")
llm.invoke("Where is Berlin?")
LangChain also offers output parsers to structure the LLM output in a format that the application may need, such as structured data types like JSON, XML, CSV, and others. To understand LangChain’s interface with LLMs in detail, read the documentation here.
Retrieval
Most enterprise AI applications are built by augmenting the LLM context using data specific to the application’s use case. To accomplish this, the relevant data needs to be first retrieved, typically using vector similarity search, and then passed to the LLM context at the generation step. This architecture, known as Retrieval Augmented Generation (RAG), can be used to build a wide range of AI applications.
While the retrieval process sounds simple, it involves a number of complex steps: loading data from a source, splitting it into chunks, converting it into vectors or vector embeddings, storing it in a vector store, and then retrieving results based on a query before the generation step.
LangChain offers a number of building blocks to make this retrieval process simpler.
- Document Loaders: LangChain offers over 100 different document loaders, including integrations with providers like Unstructured or Airbyte. It also supports loading various types of documents, such as PDFs, HTML, CSV, and code, from a range of locations like S3.
- Splitting: During the retrieval step, you typically need to retrieve only the relevant section of a document. To do this, you need to split a large document into smaller chunks. LangChain offers various document transformers that make it easy to split, combine, filter, or manipulate documents.
- Text Embeddings: A key aspect of the retrieval step is converting document chunks into vectors, which are high-dimensional numerical representations that capture the semantic meaning of the text. LangChain offers integrations with over 25 embedding providers and methods, such as FastEmbed.
- Vector Store Integration: LangChain integrates with over 50 vector stores, including specialized ones like Qdrant, and exposes a standard interface.
- Retrievers: LangChain offers various retrieval algorithms and allows you to use third-party retrieval algorithms or create custom retrievers.
- Indexing: LangChain also offers an indexing API that keeps data from any data source in sync with the vector store, helping to reduce complexities around managing unchanged content or avoiding duplicate content.
Composition
Finally, LangChain also offers building blocks that help combine external APIs, services, and LangChain primitives. For instance, it provides tools to fetch data from Wikipedia or search using Google Lens. The list of tools it offers is extremely varied.
LangChain also offers ways to build agents that use language models to decide on the sequence of actions to take.
LCEL
The primary method of building an application in LangChain is through the use of LCEL, the LangChain Expression Language. It is a declarative syntax designed to simplify the composition of chains within the LangChain framework. It provides a minimalist code layer that enables the rapid development of chains, leveraging advanced features such as streaming, asynchronous execution, and parallel processing.
LCEL is particularly useful for building chains that involve multiple language model calls, data transformations, and the integration of outputs from language models into downstream applications.
Some Use Cases of LangChain
Given the flexibility that LangChain offers, a wide range of applications can be built using the framework. Here are some examples:
RAG Applications: LangChain provides all the essential building blocks needed to build Retrieval Augmented Generation (RAG) applications. It integrates with vector stores and LLMs, streamlining the entire process of loading, chunking, and retrieving relevant sections of a document in a few lines of code.
Chatbots: LangChain offers a suite of components that streamline the process of building conversational chatbots. These include chat models, which are specifically designed for message-based interactions and provide a conversational tone suitable for chatbots.
Extracting Structured Outputs: LangChain assists in extracting structured output from data using various tools and methods. It supports multiple extraction approaches, including tool/function calling mode, JSON mode, and prompting-based extraction.
Agents: LangChain simplifies the process of building agents by providing building blocks and integration with LLMs, enabling developers to construct complex, multi-step workflows. These agents can interact with external data sources and tools, and generate dynamic and context-aware responses for various applications.
If LangChain offers such a wide range of integrations and the primary building blocks needed to build AI applications, why do we need another framework?
As Omar Khattab, PhD, Stanford and researcher at Stanford NLP, said when introducing DSPy in his talk at ‘Scale By the Bay’ in November 2023: “We can build good reliable systems with these new artifacts that are language models (LMs), but importantly, this is conditioned on us adapting them as well as stacking them well”.
DSPy: Features, Performance, and Use Cases
When building AI systems, developers need to break down the task into multiple reasoning steps, adapt language model (LM) prompts for each step until they get the right results, and then ensure that the steps work together to achieve the desired outcome.
Complex multihop pipelines, where multiple LLM calls are stacked, are messy. They involve string-based prompting tricks or prompt hacks at each step, and getting the pipeline to work is even trickier.
Additionally, the manual prompting approach is highly unscalable, as any change in the underlying language model breaks the prompts and the pipeline. LMs are highly sensitive to prompts and slight changes in wording, context, or phrasing can significantly impact the model’s output. Due to this, despite the functionality provided by frameworks like LangChain, developers often have to spend a lot of time engineering prompts to get the right results from LLMs.
How do you build a system that’s less brittle and more predictable? Enter DSPy!
DSPy is built on the paradigm that language models (LMs) should be programmed rather than prompted. The framework is designed for algorithmically optimizing and adapting LM prompts and weights, and focuses on replacing prompting techniques with a programming-centric approach.
DSPy treats the LM like a device and abstracts out the underlying complexities of prompting. To achieve this, DSPy introduces three simple building blocks:
Signatures
Signatures replace handwritten prompts and are written in natural language. They are simply declarations or specs of the behavior that you expect from the language model. Some examples are:
- question -> answer
- long_document -> summary
- context, question -> rationale, response
Rather than manually crafting complex prompts or engaging in extensive fine-tuning of LLMs, signatures allow for the automatic generation of optimized prompts.
DSPy Signatures can be specified in two ways:
Inline Signatures: Simple tasks can be defined in a concise format, like “question -> answer” for question-answering or “document -> summary” for summarization.
Class-Based Signatures: More complex tasks might require class-based signatures, which can include additional instructions or descriptions about the inputs and outputs. For example, a class for emotion classification might clearly specify the range of emotions that can be classified.
Modules
Modules take signatures as input, and automatically generate high-quality prompts. Inspired heavily from PyTorch, DSPy modules eliminate the need for crafting prompts manually.
The framework supports advanced modules like dspy.ChainOfThought, which adds step-by-step rationalization before producing an output. The output not only provides answers but also rationales. Other modules include dspy.ProgramOfThought, which outputs code whose execution results dictate the response, and dspy.ReAct, an agent that uses tools to implement signatures.
DSPy also offers modules like dspy.MultiChainComparison, which can compare multiple outputs from dspy.ChainOfThought in order to produce a final prediction. There are also utility modules like dspy.majority for aggregating responses through voting.
Modules can be composed into larger programs, and you can compose multiple modules into bigger modules. This allows you to create complex, behavior-rich applications using language models.
Optimizers
Optimizers take a set of modules that have been connected to create a pipeline, compile them into auto-optimized prompts, and maximize an outcome metric.
Essentially, optimizers are designed to generate, test, and refine prompts, and ensure that the final prompt is highly optimized for the specific dataset and task at hand. Using optimizers in the DSPy framework significantly simplifies the process of developing and refining LM applications by automating the prompt engineering process.
Building AI Applications with DSPy
A typical DSPy program requires the developer to follow the following 8 steps:
- Defining the Task: Identify the specific problem you want to solve, including the input and output formats.
- Defining the Pipeline: Plan the sequence of operations needed to solve the task. Then craft the signatures and the modules.
- Testing with Examples: Run the pipeline with a few examples to understand the initial performance. This helps in identifying immediate issues with the program and areas for improvement.
- Defining Your Data: Prepare and structure your training and validation datasets. This is needed by the optimizer for training the model and evaluating its performance accurately.
- Defining Your Metric: Choose metrics that will measure the success of your model. These metrics help the optimizer evaluate how well the model is performing.
- Collecting Zero-Shot Evaluations: Run initial evaluations without prior training to establish a baseline. This helps in understanding the model’s capabilities and limitations out of the box.
- Compiling with a DSPy Optimizer: Given the data and metric, you can now optimize the program. DSPy offers a variety of optimizers designed for different purposes. These optimizers can generate step-by-step examples, craft detailed instructions, and/or update language model prompts and weights as needed.
- Iterating: Continuously refine each aspect of your task, from the pipeline and data to the metrics and evaluations. Iteration helps in gradually improving the model’s performance and adapting to new requirements.
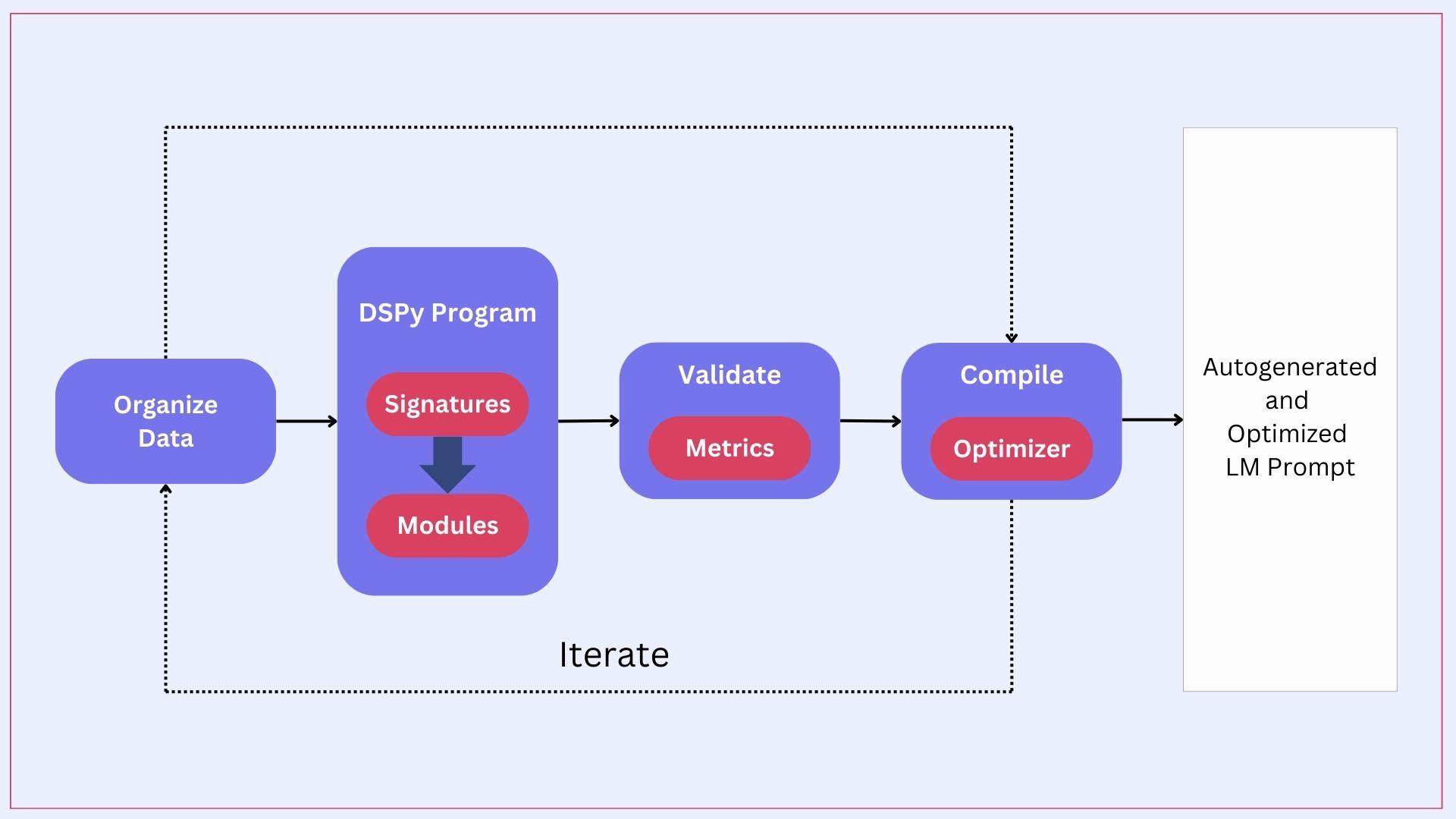
Process
Language Model Setup
Setting up the LM in DSPy is easy.
# pip install dspy
import dspy
llm = dspy.OpenAI(model='gpt-3.5-turbo-1106', max_tokens=300)
dspy.configure(lm=llm)
# Let's test this. First define a module (ChainOfThought) and assign it a signature (return an answer, given a question).
qa = dspy.ChainOfThought('question -> answer')
# Then, run with the default LM configured.
response = qa(question="Where is Paris?")
print(response.answer)
You are not restricted to using one LLM in your program; you can use multiple. DSPy can be used with both managed models such as OpenAI, Cohere, Anyscale, Together, or PremAI as well as with local LLM deployments through vLLM, Ollama, or TGI server. All LLM calls are cached by default.
Vector Store Integration (Retrieval Model)
You can easily set up Qdrant vector store to act as the retrieval model. To do so, follow these steps:
# pip install dspy-ai[qdrant]
import dspy
from dspy.retrieve.qdrant_rm import QdrantRM
from qdrant_client import QdrantClient
llm = dspy.OpenAI(model="gpt-3.5-turbo")
qdrant_client = QdrantClient()
qdrant_rm = QdrantRM("collection-name", qdrant_client, k=3)
dspy.settings.configure(lm=llm, rm=qdrant_rm)
The above code sets up DSPy to use Qdrant (localhost), with collection-name as the default retrieval client. You can now build a RAG module in the following way:
class RAG(dspy.Module):
def __init__(self, num_passages=5):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought('context, question -> answer') # using inline signature
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
Now you can use the RAG module like any Python module.
Optimizing the Pipeline
In this step, DSPy requires you to create a training dataset and a metric function, which can help validate the output of your program. Using this, DSPy tunes the parameters (i.e., the prompts and/or the LM weights) to maximize the accuracy of the RAG pipeline.
Using DSPy optimizers involves the following steps:
- Set up your DSPy program with the desired signatures and modules.
- Create a training and validation dataset, with example input and output that you expect from your DSPy program.
- Choose an appropriate optimizer such as BootstrapFewShotWithRandomSearch, MIPRO, or BootstrapFinetune.
- Create a metric function that evaluates the performance of the DSPy program. You can evaluate based on accuracy or quality of responses, or on a metric that’s relevant to your program.
- Run the optimizer with the DSPy program, metric function, and training inputs. DSPy will compile the program and automatically adjust parameters and improve performance.
- Use the compiled program to perform the task. Iterate and adapt if required.
To learn more about optimizing DSPy programs, read this.
DSPy is heavily influenced by PyTorch, and replaces complex prompting with reusable modules for common tasks. Instead of crafting specific prompts, you write code that DSPy automatically translates for the LLM. This, along with built-in optimizers, makes working with LLMs more systematic and efficient.
Use Cases of DSPy
As we saw above, DSPy can be used to create fairly complex applications which require stacking multiple LM calls without the need for prompt engineering. Even though the framework is comparatively new - it started gaining popularity since November 2023 when it was first introduced - it has created a promising new direction for LLM-based applications.
Here are some of the possible uses of DSPy:
Automating Prompt Engineering: DSPy automates the process of creating prompts for LLMs, and allows developers to focus on the core logic of their application. This is powerful as manual prompt engineering makes AI applications highly unscalable and brittle.
Building Chatbots: The modular design of DSPy makes it well-suited for creating chatbots with improved response quality and faster development cycles. DSPy’s automatic prompting and optimizers can help ensure chatbots generate consistent and informative responses across different conversation contexts.
Complex Information Retrieval Systems: DSPy programs can be easily integrated with vector stores, and used to build multi-step information retrieval systems with stacked calls to the LLM. This can be used to build highly sophisticated retrieval systems. For example, DSPy can be used to develop custom search engines that understand complex user queries and retrieve the most relevant information from vector stores.
Improving LLM Pipelines: One of the best uses of DSPy is to optimize LLM pipelines. DSPy’s modular design greatly simplifies the integration of LLMs into existing workflows. Additionally, DSPy’s built-in optimizers can help fine-tune LLM pipelines based on desired metrics.
Multi-Hop Question-Answering: Multi-hop question-answering involves answering complex questions that require reasoning over multiple pieces of information, which are often scattered across different documents or sections of text. With DSPy, users can leverage its automated prompt engineering capabilities to develop prompts that effectively guide the model on how to piece together information from various sources.
Comparative Analysis: DSPy vs LangChain
DSPy and LangChain are both powerful frameworks for building AI applications, leveraging large language models (LLMs) and vector search technology. Below is a comparative analysis of their key features, performance, and use cases:
| Feature | LangChain | DSPy |
|---|---|---|
| Core Focus | Focus on providing a large number of building blocks to simplify the development of applications that use LLMs in conjunction with user-specified data sources. | Focus on automating and modularizing LLM interactions, eliminating manual prompt engineering and improving systematic reliability. |
| Approach | Utilizes modular components and chains that can be linked together using the LangChain Expression Language (LCEL). | Streamlines LLM interaction by prioritizing programming instead of prompting, and automating prompt refinement and weight tuning. |
| Complex Pipelines | Facilitates the creation of chains using LCEL, supporting asynchronous execution and integration with various data sources and APIs. | Simplifies multi-stage reasoning pipelines using modules and optimizers, and ensures scalability through less manual intervention. |
| Optimization | Relies on user expertise for prompt engineering and chaining of multiple LLM calls. | Includes built-in optimizers that automatically tune prompts and weights, and helps bring efficiency and effectiveness in LLM pipelines. |
| Community and Support | Large open-source community with extensive documentation and examples. | Emerging framework with growing community support, and bringing a paradigm-shift in LLM prompting. |
LangChain
Strengths:
- Data Sources and APIs: LangChain supports a wide variety of data sources and APIs, and allows seamless integration with different types of data. This makes it highly versatile for various AI applications.
- LangChain provides modular components that can be chained together and allows you to create complex AI workflows. LangChain Expression Language (LCEL) lets you use declarative syntax and makes it easier to build and manage workflows.
- Since LangChain is an older framework, it has extensive documentation and thousands of examples that developers can take inspiration from.
Weaknesses:
- For projects involving complex, multi-stage reasoning tasks, LangChain requires significant manual prompt engineering. This can be time-consuming and prone to errors.
- Scalability Issues: Managing and scaling workflows that require multiple LLM calls can be pretty challenging.
- Developers need sound understanding of prompt engineering in order to build applications that require multiple calls to the LLM.
DSPy
Strengths:
- DSPy automates the process of prompt generation and optimization, and significantly reduces the need for manual prompt engineering. This makes working with LLMs easier and helps build scalable AI workflows.
- The framework includes built-in optimizers like BootstrapFewShot and MIPRO, which automatically refine prompts and adapt them to specific datasets.
- DSPy uses general-purpose modules and optimizers to simplify the complexities of prompt engineering. This can help you create complex multi-step reasoning applications easily, without worrying about the intricacies of dealing with LLMs.
- DSPy supports various LLMs, including the flexibility of using multiple LLMs in the same program.
- By focusing on programming rather than prompting, DSPy ensures higher reliability and performance for AI applications, particularly those that require complex multi-stage reasoning.
Weaknesses:
- As a newer framework, DSPy has a smaller community compared to LangChain. This means you will have limited availability of resources, examples, and community support.
- Although DSPy offers tutorials and guides, its documentation is less extensive than LangChain’s, which can pose challenges when you start.
- When starting with DSPy, you may feel limited to the paradigms and modules it provides.
Selecting the Ideal Framework for Your AI Project
When deciding between DSPy and LangChain for your AI project, you should consider the problem statement and choose the framework that best aligns with your project goals.
Here are some guidelines:
Project Type
LangChain: LangChain is ideal for projects that require extensive integration with multiple data sources and APIs, especially projects that benefit from the wide range of document loaders, vector stores, and retrieval algorithms that it supports.
DSPy: DSPy is best suited for projects that involve complex multi-stage reasoning pipelines or those that may eventually need stacked LLM calls. DSPy’s systematic approach to prompt engineering and its ability to optimize LLM interactions can help create highly reliable AI applications.
Technical Expertise
LangChain: As the complexity of the application grows, LangChain requires a good understanding of prompt engineering and expertise in chaining multiple LLM calls.
DSPy: Since DSPy is designed to abstract away the complexities of prompt engineering, it makes it easier for developers to focus on high-level logic rather than low-level prompt crafting.
Community and Support
LangChain: LangChain boasts a large and active community with extensive documentation, examples, and active contributions, and you will find it easier to get going.
DSPy: Although newer and with a smaller community, DSPy is growing rapidly and offers tutorials and guides for some of the key use cases. DSPy may be more challenging to get started with, but its architecture makes it highly scalable.
Use Case Scenarios
Retrieval Augmented Generation (RAG) Applications
LangChain: Excellent for building simple RAG applications due to its robust support for vector stores, document loaders, and retrieval algorithms.
DSPy: Suitable for RAG applications requiring high reliability and automated prompt optimization, ensuring consistent performance across complex retrieval tasks.
Chatbots and Conversational AI
LangChain: Provides a wide range of components for building conversational AI, making it easy to integrate LLMs with external APIs and services.
DSPy: Ideal for developing chatbots that need to handle complex, multi-stage conversations with high reliability and performance. DSPy’s automated optimizations ensure consistent and contextually accurate responses.
Complex Information Retrieval Systems
LangChain: Effective for projects that require seamless integration with various data sources and sophisticated retrieval capabilities.
DSPy: Best for systems that involve complex multi-step retrieval processes, where prompt optimization and modular design can significantly enhance performance and reliability.
You can also choose to combine and use the best features of both. In fact, LangChain has released an integration with DSPy to simplify this process. This allows you to use some of the utility functions that LangChain provides, such as text splitter, directory loaders, or integrations with other data sources while using DSPy for the LM interactions.
Level Up Your AI Projects with Advanced Frameworks
LangChain and DSPy both offer unique capabilities and can help you build powerful AI applications. Qdrant integrates with both LangChain and DSPy, allowing you to leverage its performance, efficiency and security features in either scenario. LangChain is ideal for projects that require extensive integration with various data sources and APIs. On the other hand, DSPy offers a powerful paradigm for building complex multi-stage applications. For pulling together an AI application that doesn’t require much prompt engineering, use LangChain. However, pick DSPy when you need a systematic approach to prompt optimization and modular design, and need robustness and scalability for complex, multi-stage reasoning applications.
References
https://python.langchain.com/v0.1/docs/get_started/introduction
